VSCode 中文快捷键跳转解决方案
记一次 VSCode 插件的开发(魔改)过程
Posted on
之前的文章介绍过,我常用 VSCode 来进行 LaTeX 写作。但是当进行中文写作时,VSCode 的一个问题常常让我感到不快:对于英文的内容,我们可以使用 ctrl + 方向键 来进行以单词为单位的跳转(如果只用方向键的话,效果是以字符为单位跳转),ctrl + backspace 可以做到以单词为单位的删除,等等。然而由于 VSCode 机制的原因,这样的快捷健对于中文的效果是很糟糕的:它会将一整段中文识别为一个单词,这导致跳转 / 删除的范围是一整段,这一般并不是我们需要的。本文将记录我解决这一问题的过程。
#Introduction
VSCode 会将若干个连续的,非空白 / 英文标点(含下划线,不含连接符)符号的字符识别为一个单词。通过这样的单词划分,VSCode 实现了下述的一些快捷功能:
ctrl+ 方向键:以单词为单位跳转ctrl+delete/backspace:以单词为单位删除ctrl+shift+ 方向键:以单词为单位增加 / 减少选区ctrl+F搜索功能:”匹配整个单词“ 选项- 光标位于一个单词上时,改变这个单词在文中所有 occurrences 的背景颜色,并且在滚动条上标识,对于之前出现过的单词提供自动补全
- 双击选中一个单词
由于上面的功能都依赖于单词的识别,因此它们在中文(以及其它的众多东亚文字)环境下都无法正常工作。我们希望通过 VSCode 强大的插件系统解决(或者缓解)这个问题。通过在 Marketplace 上的搜索,我找到了两个和这个问题相关的插件:
- Quick Chinese Deletion:这个插件通过 Node-Segment 来进行中文分词,然后可以通过
ctrl+delete来进行以词为单位的删除 - Japanese Word Handler:这个插件通过识别平假名、片假名之间的切换判断日语单词的间隔,从而对日文实现了上文提到的 1, 2, 3 功能(4, 5, 6 的话 VSCode 目前还没有提供 API 支持,所以比较难实现)
可以看到,插件 1 能提供比较完善的中文分词,但是对于功能的支持数量不佳;插件 2 对日文提供了比较粗糙的分词,但是功能比较完善。
#First step
由于不想重复造轮子,因此我们考虑魔改上面两个插件中的一个来达成我们的目的。考虑到第二个插件已经考虑到了绝大部分逻辑,因此从它下手比较方便。
为了实现这个功能,主要需要实现的逻辑是找到当前光标所在的词的左边界和右边界。Japanese Word Handler 插件实现这一功能的方式比较直接,以寻找左边界为例,依次执行如下步骤:
- 如果光标位于行首,检察这一行是否为第一行,如果是的话那么左边界就是当前的光标位置,否则是上一行的行尾。
- 如果光标的左侧是空白字符,那么先将光标不断左移,直至没有空白字符为止。
- 检察光标左侧字符的类别,将光标不断左移,直至光标左侧的字符类别发生改变为止。
其中字符的类别包括 拉丁字符 / 数字,空白字符,标点符号,平假名,片假名,其它,分隔符(分割单词的符号),无效字符(表示光标位于实际上不存位置时的特殊类别)。
enum CharClass {
Alnum, // alphabet & numbers
Whitespace,
Punctuation,
Hiragana,
Katakana,
Other,
Separator, // word separators
Invalid
}为了将这个逻辑更改为对于中文也适用的模式,首先在上面的类别中添加汉字 Han。下面考虑如何判别汉字。
js 中的 charCodeAt( i: number): number 函数能给出字符串在某一位上字符的 Unicode 编码值(0 到 0xffff),因此应当使用 Unicode-16 编码中汉字的编码范围来识别汉字。然而在查阅相关的资料之后发现,字符编码是一件很复杂的事情,特别是对于东亚文字来说。“汉字”这个概念不仅出现在中文当中,而且由于历史原因,汉字在日文中也是很重要的组成部分,而在韩文中汉字也偶有出现,除此之外的例子,还有越南的喃字、方块壮字等等。在不同语言中的汉字可能具有相同的出处,但是字型不同,例如
“次”字的左旁,韩国采用传统字形,首笔为横,次笔为挑;台湾教育部作两横;大陆、日本、香港等则作“冫”(俗称两点水)
Unicode 使用“中日韩统一表意文字”(CJK Unified Ideographs)标准来处理这些“汉字”的编码。在这一标准中,对于汉字收录的处理使用表意文字认同原则(Han Unification Rule,又称表意文字统合原则)与字源分离原则(Source Separation Rule,又称原规格分离原则)。一个字(character)如果在不同语言中具有不同的字型(glyph),那么这些不同的字型会被编为同一个编码,由字体来负责处理显示不同的字型。而如果一个字在同一个语言中具有多种不同的字型,那么这些不同的字型会被编为多个编码。
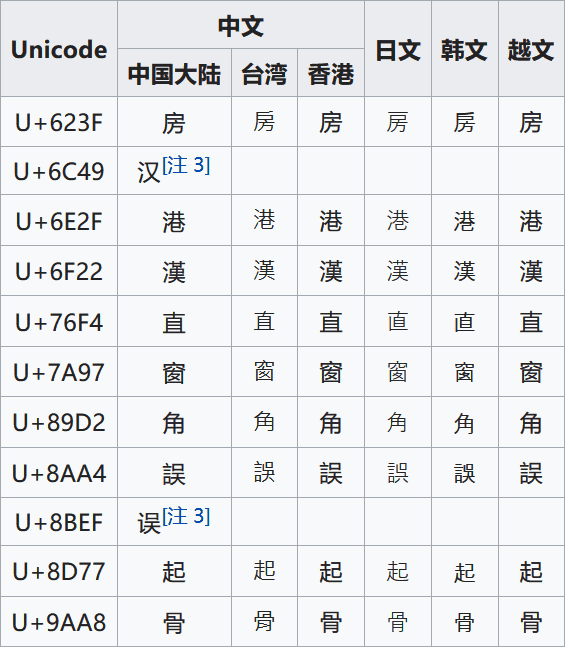
(上图图源和上文的主要参考来源均为 wiki)
由此可见,“汉字”在 Unicode 中不是一个明确的概念,Unicode 中只有 CJK 这个概念。方便起见,我们只能将所有的 CJK 字符全部当作汉字来处理了。Unicode 中收录的 CJK 字符分为若干个区(block),基本的区域 CJK Unified Ideographs (编码范围 0x4E00–0x9FFF)包含了两万余个 CJK 字符,除此之外还有若干个扩展区域(目前有 CJK Unified Ideographs Extension A ~ CJK Unified Ideographs Extension F)收录一些比较生僻的字符。因此,最后选取的判别汉字的函数如下:
function isHanChar(charCode : number) : boolean {
return 0x3400 <= charCode && charCode <= 0x4dbf
// CJK Unified Ideographs Extension A
|| 0x4e00 <= charCode && charCode <= 0x9fff
// CJK Unified Ideographs
|| 0x20000 <= charCode && charCode <= 0x2a6df
// CJK Unified Ideographs Extension B
|| 0x2a700 <= charCode && charCode <= 0x2ebef;
}将上面的代码扔进 Japanese Word Handler 的代码中稍作整理就可以得到一个简单的,对汉字适用的插件版本了,在这个版本中,连续的一串汉字会被识别为一个单词,换言之,它是将一个句子识别为一个词。这样的效果在很多情况下都是够用的。
#Word segmentation
简单的修补并不能让人满意,因此我考虑将分词的功能也加上去。node.js 生态下,有两个分词库比较常用,一个是基于 python 生态下著名的分词库 jieba 移植而成的 nodejieba,另一个是上文提到的 Quick Chinese Deletion 插件所使用的 node-segment。由于 nodejieba 宣称性能比较高,因此我本来准备使用 nodejieba,然而在使用的过程中发现出了一些问题。
nodejieba 包含一些使用 c / c++ 编写的扩展用以提高性能,我在使用 npm 安装 nodejieba 的时候它会下载这些 c / c++ 源代码,然后在本机上编译为二进制文件。然而 VSCode 在打包插件的时候会将依赖的库也一起打包进去(后文还会提到这个问题),也就是说,这些二进制文件的执行环境和编译环境是不同的,即使在同一台设备上,也会随着 node.js 版本的变化而发生改变,例如,我编译的时候 node 的版本为 79,但是 VSCode 自己是用版本为 73 的 node 编译的,那么在载入 nodejieba 库的时候,会因为编译环境的不同而报错。要想解决这个问题,似乎唯一的方法是保持自己使用的 node 的版本和 VSCode 编译时使用的版本一致,然而这是很难做到的,因为不同插件用户所使用的 VSCode 版本就可能是不一致的。
当有了分词库之后,剩下的就是对于代码逻辑的处理了。由于 Japanese Word Handler 作者在一些核心函数上实现的逻辑有些混乱,几个作用基本平行的函数写出来的 style 完全不一样,不方便修改,所以先把那几个函数都重写了一遍。对于其它部分,作者原来的架构做得还是不错的,不同部分的解耦程度很高,修改起来方便。
在引入中文分词的功能之后,这个插件已经基本可是投入使用了。然而,在此之前我又遇到了一个奇怪的 bug:当我使用 F5 进行调试的时候,插件能够正常使用,然而当我使用 vsce package 将插件打包为 .vsix 文件,然后使用 Extensions: Install from VSIX 命令安装到我的 VSCode 上之后,插件完全失灵了,在使用上面定义的快捷键的时候会弹出提示框 Command ‘xxxx’ not found 。无论我在函数 function activate(context: vscode.ExtensionContext) 中插入任何逻辑,它都不会被运行。在经过若干个小时不断的回滚 debug 之后,我终于发现了我所犯下地幼稚的错误:
在 package.json (项目的配置文件)中,我把 segment 这个库加入到了 devDependencies 中,然而这个配置只是代表在开发时的库依赖,在用 vsce 打包时这个库是不会被打包进去的,而用户安装时更不会自动安装这个库。因此当我在全局环境下导入这个库 const Segment = require(‘segment’); 时会抛出异常,从而整个插件的执行都会被中止,activate 函数的逻辑自然也不会被执行。为了解决这个问题,只需要在 package.json 中加上:
"dependencies": {
"segment": "^0.1.3"
}即可。
最后,为了增强插件的可定制性,我提供了一个配置项 cjkWordHandler.chinesePartitioningRule,可以定制分词时所使用的策略,默认的策略 By words 是使用分词库进行分词,By sentences 是根据汉字和标点符号之间的变化从而将一个句子识别为一个词,而 By characters 则是逐字地进行跳转。
至此,整个插件的功能就基本完成了。完善一下 README,画了一个草率的 icon 之后就可以提交到 VSCode Marketplace 了。
#Release
目前该插件已经发布至 VSCode Marketplace,插件名为 CJK word handler。这个插件基本完全解决了上文中提到的问题 1, 2, 3,后续还会加入一些优化和改进。欢迎有需求的读者安装使用。如果在使用过程中发现 bug 可以前往 GitHub 提出 Issue。